加深对脏读、脏写、可重复读、幻读的理解
关于相关术语的专业解释,请自行百度了解,本文皆本人自己结合参考书和自己的理解所做的阐述,如有不严谨之处,还请多多指教。
事务有四种基本特性,叫ACID,它们分别是:
Atomicity-原子性,Consistency-一致性,Isolation-隔离性,Durability-持久性。
1、原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位。
2、一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。
3、隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
4、持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
而其中的隔离性特点,说的就是在并发的多个事务中事务之间是互不影响的这种情形。Mysql里支持四种不同的隔离级别,这也为解决并发问题提供了选择。
为了更好的理解隔离级别,我们需要给每个会话设置不同的隔离级别,从而辅助自己实践。
相关语法:
SET GLOBAL TRANSACTION ISOLATION LEVEL ;
SET SESSION TRANSACTION ISOLATION LEVEL ;
SET TRANSACTION ISOLATION LEVEL ;
上面语法设置的值选项就是mysql的四种隔离级别:
READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE
由于mysql默认隔离级别是可重复读(Repeatable Read):
show variables like '%tx_isolation%'; //查询数据库当前的隔离级别
所以实践过程中咱们需要给会话设置隔离级别,就如下所示:
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED
其中全局事务(global transaction)的隔离级别设置,是对现有已经建好的会话是没有影响的。
set global tx_isolation='READ-COMMITTED'
select @@tx_isolation;
show variables like 'tx_isolation';
注意:设置的全局默认事务隔离级别适用于从设置时起所有新建立的会话连接。现有连接不受影响。
有关实践过程,这里不再赘述,请参考这位博主的文章:MySQL的四种事务隔离级别
接着主要着重帮助自己加强对脏读、脏写、可重复读、更新丢失、幻读、写偏离等的理解。
在此先上一张隔离级别的对比图:
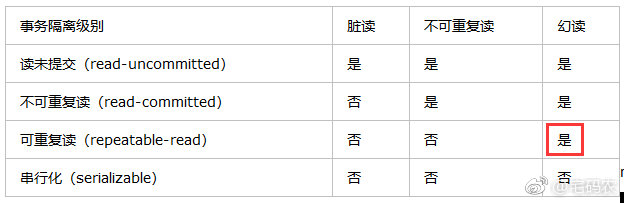
(图中红框仅表示提醒)
脏读:
如果一个事务A向数据库写了数据,但事务还没提交或终止,另一个事务B就看到了事务A写进数据库的数据,这就是脏读。
经过前面的实践,就能得知,在读未提交(Read Uncommitted)隔离级别下,是会出现脏读的。
仔细体会读未提交(Read Uncommitted)隔离级别的命名--读取事务还未提交的数据,就会发现说的就是脏读。
脏读会导致什么问题呢?
1. 给用户带来数据混乱的感觉。
例如在一个多对象的事务A里,A需要生成一条邮件发送记录,同时需要在用户未读取邮件的计数里+1,这里涉及两张表的业务情形,就是对多对象的诠释。如果事务A insert邮件发送记录时(还没执行计数+1这个后面的操作),就被事务B查询了,可事务B此时看到的邮件计数还是+1之前的,这样就会导致事务B看到的未读取邮件条数与计数数据不一致。
2. 让用户看到根本不存在的数据。
例如事务A 是转账业务,由乔峰转给段誉,在更新段誉账户余额时(假定此时事务A还未提交),事务B下段誉正查询自己账户余额,发现乔峰给自己转账了。可是事务A下乔峰突然意识段誉是大理太子,家底丰实得很,于是撤销了转账(事务A回退或终止)。整个过程,段誉就看到了根本不存在的转账记录。本以为钱来了,结果还没眨眼就没了,你说用户是段誉,生不生气。
脏写:
当两个事务同时尝试去更新某一条数据记录时,就肯定会存在一个先一个后。而当事务A更新时,事务A还没提交,事务B就也过来进行更新,覆盖了事务A提交的更新数据,这就是脏写。
文上提到的4种隔离级别下,都不存在脏写情况。因为在这些隔离级别下,当两个事务A和B尝试去更新同一条数据时,假定A先更新数据,会对更新的数据行记录加上排他锁(也叫写锁,悲观锁),除非事务A提交或终止从而释放排他锁,否则事务B都是无法更新数据的。(设计数据密集型应用只是说读提交隔离级别一定可以杜绝脏写问题,并未提到读未提交隔离级别,经过实践,读未提交下事务B的更新操作也是需要等待事务A的排他锁释放,才得以执行)
脏写会带来什么问题呢?
脏写是会导致更新丢失的一种情形,具体会带来什么问题,可看后面的更新丢失这块内容。
可重复读:
我本来认为,不可重复读之下的结果也正是所谓的正确结果,也就没必要去避讳。就如下图里的Alice,只要再查询下Account1下的余额,就可以拼出正确的总额600+400 = 1000。
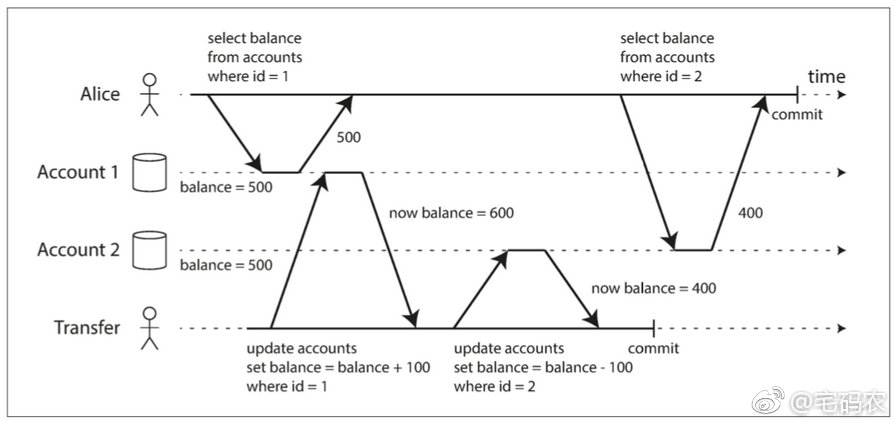
如图所示,假设转账行为是由银行操控的,Alice一开始看两个账户的总额是500+500,后又无意看到Account2账户变为了400,这种Alice纳罕总额怎么从1000变为了900的现象,我们就称之为读偏离(read skew)。但我们知道,Alice的Account2下的钱的的确确是400,并没有说少了的100元被谁给私吞了。所以说,这种现象勉强还是可以接受的,毕竟Alice的钱也没变少,只要再查询一次Account1,就能释疑了。
那Mysql为啥默认级别是可重复读呢,不是读提交呢,说明可重复读还是有非常的必要。通过以下几点可以看出:
1. mysql分布式,多节点同步数据时,可重复读可以保证多个节点数据的一致性。具体请参考下图:
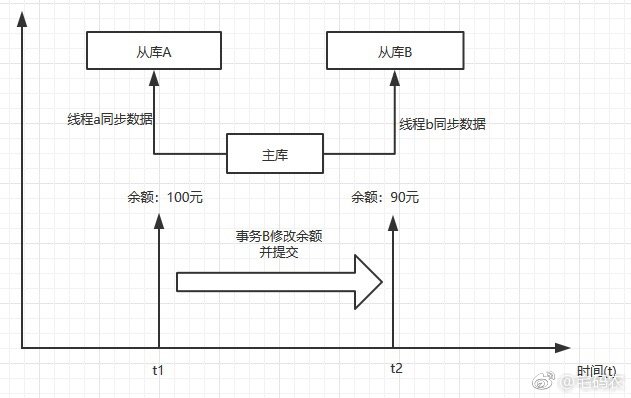
图中有两个从库A和B,主库同步数据时,会有多个事务并发的执行,由于不可重复读的特点,就会导致从库A同步到的数据里我的余额是100元,而从库B里我的余额数据是90元,从而导致AB两个从库之间以及主库和从库A之间数据的不一致。
2. 备份数据库时,不可重复读会导致备份一部分是旧数据一部分是更新后的新数据,从这样的备份来恢复数据,就会导致数据的不一致(例如钱变少了,此点本人也不是很清楚,大概了解即可)。
3.对于分析查询,需要的就是遍历大量数据来进行分析和数据的完整性检查。如果是不可重复读,就会导致一前一后数据不一致,影响到分析结果。
更新丢失:
当多个事务并发写同一数据时,先执行的事务所写的数据会被后写的覆盖,这也就是更新丢失。前面的脏写情形,就属于会导致更新丢失问题的一种情形。
除了这个,更新丢失主要发生在read-modify-write类型的事务当中:就是要先查询数据,然后计算新的数据,最后写回新的数据。下面是几个具体的情形例子:
1. 数值更新,例如计数或账户余额更新(先要查询当前值,再计算出要更新的值,最后执行更新操作写进数据库)
2. 更新一个复杂的数据,例如要往json对象里添加数据。(先查询获取json对象数据进行解析,再添加数据得到新的数据写回数据库)
3. 两个用户同时编辑Wiki保存wiki内容。
结合读未提交和读提交的区别就可知道,带来更新丢失的根本原因:
在读提交以及更高级的隔离级别下,只要事务A没有提交,事务B永远也无法查到事务A所做的更新,从而事务B在计算要更新的数据时,必定忽略掉了事务A所产生的变更。
在读未提交下实践,只要事务B的查询操作是发生在事务A的更新操作之后,就不会有更新丢失问题。但前提是要保证,事务B的查询操作是发生在事务A的更新操作之后。这很难控制,所以说读未提交下也是需要应对更新丢失问题的。
针对这个问题,数据库给了一些解决方法:
1.原子写操作。
就是将上面的read-modify-write情形下的3步骤,直接转化为1个步骤来执行。下面就是两种情形的mysql语句对比:
原子写操作(atomic write operations):
update news set counter = counter + 1 where id = 1;
查询-计算-更新(read-modify-write):
select counter from news;
new_counter = counter + 1 //此行逻辑由程序语言代码(php,java等)执行
update news set counter = new_counter where id = 1;
用过PHP框架的就知道,框架原本支持的都采用查询-计算-更新这种方式,下面是phalcon框架的例子:
use PhalconMvcModelTransactionFailed as TxFailed;
use PhalconMvcModelTransactionManager as TxManager;
$m = new TxManager();
$t = $m->get();
$model_wallet = new Wallet();
$row = $model_wallet->findFirst("user_id='".$uid."'");
$model_wallet->setTransaction($t);
$row->money = $row->money + 100;
$row->operation_time = date("Y-m-d H:i:s");
if(!$row->save()){
$t->rollback();
}else{
$t->commit();
}
所以使用框架时,就要注意这种写法在并发情形下带来的潜在数据更新丢失的问题。
2.加锁(Explicit locking,显示锁定)
通过for update来给即将更新的数据记录添加锁。也就是说事务A下执行查询时,用select for update,那么事务B下的select for update就无法进行,只有等待事务A提交或终止,事务B才得以进行。这样就相当于将并发的两个事务给串行化了,事务B查询的结果一定是在事务A提交之后,从而解决了数据更新丢失问题。
mysql下有select ... for update 和select ... lock in share mode两种显示加锁的语句,具体用途这里就不拓展了。
3.自动检测
方法1和2实质上都是将事务给串行化了。自动检测说的就是当检测到事务A造成更新丢失问题,就立即终止事务A,让事务A再一次尝试查询-计算-更新的流程,事务仍然是并行执行的。
PostgreSQL的可重复读,Oracle的串行以及SQL Server的快照隔离能够自动检测更新丢失,但Mysql的Innodb引擎下的可重复读没有此功能。
4.CAS,比较和设置(compare and set)
说简单点,就是在sql更新语句里加一个判断原本旧数据的条件,例如:
update news set counter = 30 where id = 1 and counter = 29; //29是一开始的文章点赞数
如果两个事务A和B,现在都要对id=1的新闻文章进行点赞操作,只要其中任何一个事务执行了更新操作,另一个事务执行时counter=29的条件都不会满足,从而就规避了更新丢失的问题。
但是有的数据库where条件里counter获取的本就是旧的快照数据,即不是某一个事务更新后的新数据,那这里的更新丢失问题还是要发生的了。
经过实践,mysql下可重复读隔离级别下,使用此方法,的确可以避免更新丢失问题。一旦事务A提交(对counter做更新),事务B里的类似counter=29的判断就不满足了,如此一来,事务B的写入操作就没有执行成功,就更不用说造成数据的更新丢失了。(实践里,事务A不提交,事务B里的更新操作会一直等待事务A的排它锁释放,否则是不会执行的)
5.冲突解决(待完善)
好啦,最后就来说说幻读的问题。
幻读(phantom):
看网上很多博客,都对幻读的理解不太准确。他们的理解可见此链接进行了解:MySQL的InnoDB的幻读问题
通过提交事务B之后来发现事务A出现莫名奇妙的数据遗失或数据增多,这个实践中已经涉及到事务B的提交操作,这也就已经确定了对幻读的误解。
当事务A和B各自写入一笔数据(不像更新丢失里事务A和B是往同一笔记录写入数据),破坏了潜在的竞争条件,造成的结果我们称之为“写偏离”(write skew),而造成这种结果的事务B里的查询操作的结果,才是我们所说的幻读。(至于幻读的前提是不是得一定导致了写偏离,这个待确定,现姑且当做是的)
由上可见,幻读出现的前提是出现了写偏离,而出现写偏离是只有当事务A和B都是read-write型事务时才会出现的,这也是为何有的书上说快照隔离级别下read-only型事务是没有幻读的,read-write型事务才导致幻读。
什么样的结果是写偏离?
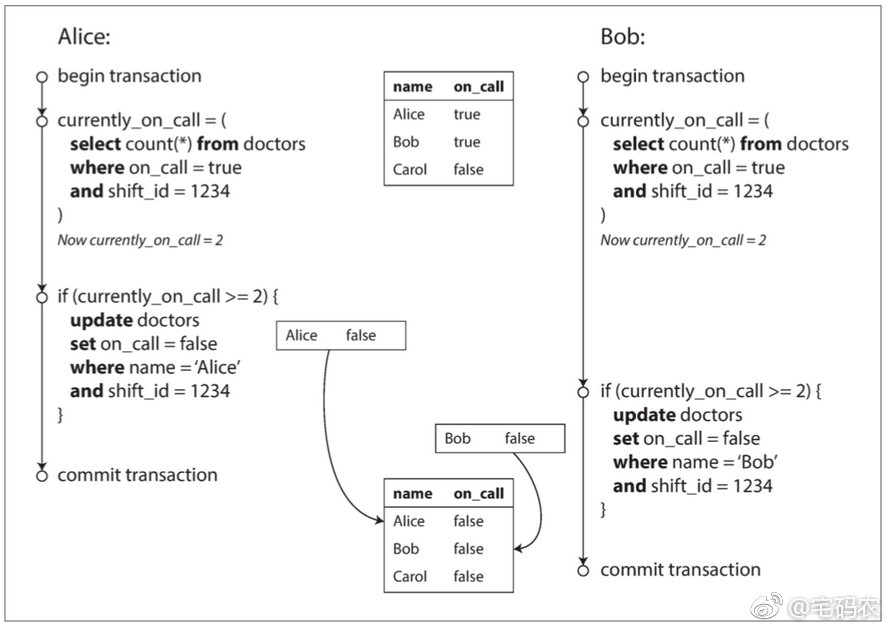
如图所示,一个医院每个班次必须有一个医生值班,所以每个医生请假的前提是当下该班次必须至少有两个医生值班,可是图中Alice和Bob很遗憾的同时点击了提交请假的按钮,导致最终1234班次无人守班,这就是破坏了潜在的竞争条件----必须至少要有一人值班,造成的这种结果,就是我们上述所说的写偏离。
假设Alice下的事务是先执行的,那么Bob下执行的查询1234班次在班的医生人数结果导致Bob也能请假,这就对潜在的竞争条件造成了破坏,我们就称Bob下事务的查询操作带来了幻读现象。
我们再总结一下写偏离和更新丢失的区别:
更新丢失是多个事务并发写同一笔数据记录造成的。 而写偏离是多个事务并发写不同数据记录影响到了潜在的竞争条件而造成的。
写偏离的情景还有:
1. 抢注用户名,两个用户同时抢注某一个用户名并且都成功了,破坏了用户名必须唯一性的潜在竞争条件。
2. 游戏里多人移动不同人物到同一位置,破坏了某一时刻某一位置只允许一个人物的潜在竞争条件。
那针对这些写偏离问题,该如何解决呢?
上文中的医生请假问题,我们可以用select...for update,就保证了第二个事务执行更新操作时必须先等待第一个事务释放排它锁。
可是这方法对于游戏移动人物位置就不适用了,因为select查询有结果才能用for update来加排它锁,而游戏里移动人物select操作结果是要保证在某一时刻某一位置必须没有人物,也就是select查询根本没有结果,就更不用谈加排它锁了。
针对这种情形,有一种物化冲突(Materialiing conflicts)的解决方法。
就是既然select查询没有结果供添加排它锁来保证串行执行,那我就想方法让select查询有结果。
针对多人游戏这个例子,假设画面是1280*720且由1*1的像素组成的屏幕,游戏人物有貂蝉、吕布、虞姬和项羽,时间维度以秒为单位,游戏开始时间从0开始计时。如此下来,我们就可以先创建一张表的数据如下:
| 时间 | x轴 | y轴 | 英雄 |
| 1 | 1 | 1 | 貂蝉 |
| 1 | 1 | 1 | 吕布 |
| 1 | 1 | 1 | 虞姬 |
| 1 | 1 | 1 | 项羽 |
| 2 | 1 | 1 | 貂蝉 |
| 2 | 1 | 1 | 吕布 |
| 2 | 1 | 1 | 虞姬 |
将任意秒任意位置可能出现的英雄情形全都列举出来,在多个事务并发移动英雄人物时,就给某一时间某一位置的记录加上for update,以上表只提供添加排它锁,不做实际修改和更新。例如:
//如此就能保证在第1秒(1,1)这个同一位置绝对不会出现多个英雄
select * from table_name where time =1 and x = 1 and y =1 for update
当然解决这个问题,还有一种方法就是采用串行化隔离级别了,也是最高的隔离级别,简单理解就是严格确保了事务串行执行,避免了脏读幻读现象,但是由于性能问题,实际生产环境很少用到。这个我以后再好好了解,本文就不细说了。