上一篇:安装photoshop软件时,遇到了以下问题(2017-09-06 16:31:56)
下一篇:画里的人(2017-09-10 22:28:48)
文章大纲
无损截取html生成文章摘要系列1_栈
2017-09-09 21:54:08
之前网上复制了一个摘要算法,一直使用正常。最近写的一篇前500字里含有超链接,就导致摘要生成有误,从而影响了前端样式。所以后面打算自己写,想起大学编译原理匹配表达式的大致思想,就决定采用栈的思想试试。
实现目标:对常用富文本编辑器(ueditor,kindeditor etc)编辑好的文档进行一定数目字符的截取,保留原始html标签,使摘要在前端正常显示。
问题分解:
1.如何区分src及href等里路径里的斜杠‘/’和html里闭合标签的斜杠‘/’
2.如何判断截取好的字符串其中html标签完整匹配。
以下是算法思想里的重要描述,可能不够准确,有错误之处,还望指正。
1.不是以‘</>'形式出现的斜杠,就不是html闭合标签的斜杠。
2.遍历时,上一个字符是‘<’,当前字符是‘/’,则一定代表html的闭合标签来了。
例如遍历<span>无损截取html</span>时,遍历到‘/’时,从右往左看,就将‘<’,‘>’依次出栈
3.br, hr,img等无需要求成对出现的html标签,配对方式为‘<’与'>'。
例如遍历<img src="http://xxxxxx" />时,遍历到‘>’时,判断之前拼接的字符串由img引导,就将最开始的‘<’出栈
下面是本人根据算法思想画的大致流程图:
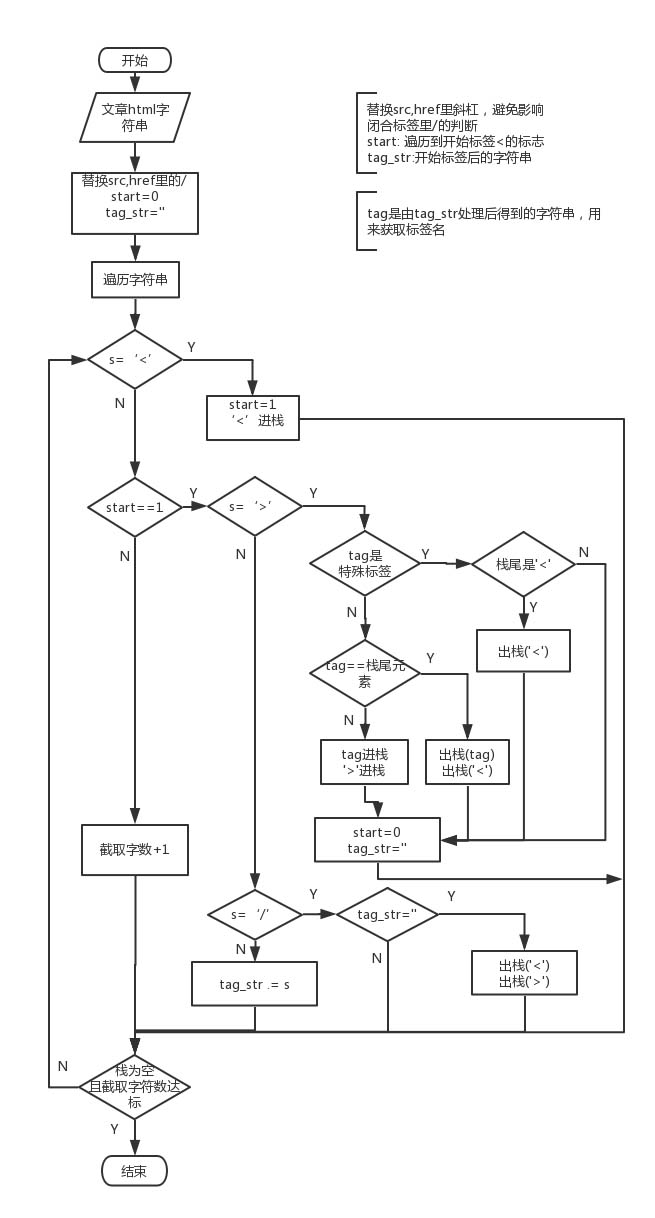
下面是本人用PHP实现的代码,仅供参考
function blog_clip($o_body, $target_clip_size = 500)
{
// log::record($o_body);
$pattern = '/[^\<](\/)[^>]/i';
$body = preg_replace_callback($pattern, function($matches){
return preg_replace('/\//i', '@', $matches[0]);
}, htmlspecialchars_decode($o_body) );
// log::record($body);
$now_clip_size = 0;
$o_size = mb_strlen($body, 'utf-8');
if($o_size <= $target_clip_size) return $o_body;
$stack_arr = array();
$html_str = '';
$is_start = 0;
$tags_special = array('img','br','hr');
$clip_index = 0;
for($i=0; $i < $o_size; $i++){
$char = mb_substr($body, $i, 1);
$stack_length = count($stack_arr);
if( '<' == $char ){
array_push($stack_arr, $char);
$is_start = 1;
}else if( 1 == $is_start){
if( '>' == $char ){
$tag = is_htmltag($html_str);
if( in_array($tag, $tags_special) ){
//是特殊tag时,若栈尾是'<'就弹出
if($stack_length > 0 && '<' == $stack_arr[$stack_length-1]){
array_pop($stack_arr);
}
}else{
//tag与栈尾元素一致,则弹出
if($tag == $stack_arr[$stack_length-1]){
array_pop($stack_arr);
array_pop($stack_arr); //弹出了标签名,接着一定可以弹出'<'
}else{
array_push($stack_arr, $tag);
array_push($stack_arr, $char);
}
}
$is_start = 0;
$html_str = '';
}else if( '/' == $char ){
//紧跟开始标签'<'之后,表示dom结点结束
if( '' == trim($html_str) ){
//先弹出'<',后弹出'>'
array_pop($stack_arr);
array_pop($stack_arr);
}
}else{
//拼接html标签字符串
$html_str .= $char;
}
}else{
// 非 html 代码才记数
$now_clip_size++;
}
// echo $i."<br>";
// echo $now_clip_size."<br>";
if(empty($stack_arr) && $now_clip_size >= $target_clip_size){
$clip_index = $i;
break;
}
}
$summary = mb_substr($body, 0, $clip_index+1);
$new_summary = preg_replace('/\@/i', '/', $summary);
return htmlspecialchars($new_summary);
}
function is_htmltag($html_str){
$trim_str = trim($html_str);
$ex_arr = explode(' ', $trim_str);
$tag_name = $ex_arr[0];
$strip_str = strip_tags(trim('<'.$tag_name.'>'));
if(0 == strlen($strip_str)){
return $tag_name;
}else{
return false;
}
}
目前测试了几篇文章,摘要获取正常。后续若发现问题,继续完善。
上一篇:安装photoshop软件时,遇到了以下问题(2017-09-06 16:31:56)
下一篇:画里的人(2017-09-10 22:28:48)
我要评论
评论列表