mysql:命令实践学习系列之一
命令只要一段时间没敲就忘了,有的真的是太久没用生疏了,有的则是因为根本不曾记住过。
本文实践相关表的sql语句:
//学生成绩表 CREATE TABLE `student_score` ( `record_id` VARCHAR(36) NOT NULL, `s_id` INT(11) NOT NULL, `subject_id` INT(11) NOT NULL, `score` DECIMAL(5,2) NOT NULL DEFAULT '0.00', `score_date` DATE NOT NULL DEFAULT '2018-10-12', PRIMARY KEY (`record_id`), INDEX `subject_id` (`subject_id`), CONSTRAINT `student_fk` FOREIGN KEY (`subject_id`) REFERENCES `subject` (`subject_id`) ) COLLATE='utf8_general_ci' ENGINE=InnoDB ;
然后再执行下面sql语句来添加两笔数据:
insert into student_score(record_id,s_id,subject_id,score,score_date) values('43739794dfs',1000000,1,98, '2018-10-26'); insert into student_score(record_id,s_id,subject_id,score,score_date) values('ddfo97sfdfk',1000001,1,65, '2018-10-26'); ok,现在就让我们在上表的基础上进行实践。
1. on duplicate key update的用法。
先来看看常用的几种写法:
INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1; INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c= VALUES(c); //就是前面的值3 INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c= 100; //直接更新为固定值
此命令的用途: db里有重复记录时就更新,没有则新增数据。
所以此命令的前提是需要有主键(primary key)或唯一键,以此才能判断记录是否重复。
现在表的主键是record_id,执行如下SQL_MAIN语句,就会发现学生1000001的科目1的成绩变化:65->89。

SQL_MAIN(文章后面就用这个名称指代如下sql):
insert into student_score(record_id,s_id,subject_id,score,score_date) values('ddfo97sfdfk',1000001,1,89, '2018-10-26') on duplicate key update score=values(score) 现在我们去掉record_id的主键,再执行上面的命令SQL_MAIN。
alter table student_score drop primary key; //删除主键
由于一张表只能含有一个主键,所以删除主键的命令里不需要主键列名。
执行后,你会发现db里另外新增了一条record_id一模一样的记录。
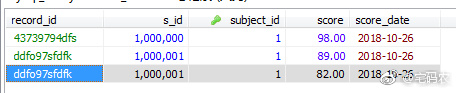
这也就验证了前面说的:
使用on duplicate key update的前提是要求数据库表有主键(primary key)或唯一键
删掉刚才生成的重复数据,让我们继续。
一个学生在某个时间点进行某科目的考试,拿到相应的考试成绩。可以分析出:
s_id, subject_id, score_date这3列可以确定数据的唯一性。
现在我们就建个复合主键。复合主键是什么,戳这里,
alter table student_score add primary key (s_id,subject_id, score_date)
再执行上面SQL_MAIN语句,把其中分值改为82,就可以看到更新效果了,如下图:

如果上面record_id列的主键没删掉,则上面复合主键的添加会报错,因为一张表只能有一个主键。
不过我们可以用唯一索引替代。
alter table student_score add unique index (s_id,subject_id, score_date)
on duplicate key的用法就实践到此为止了。
2. 添加创建时间与更新时间的栏位。
//添加创建时间,有current_timestamp这个默认值,时间会自动生成 alter table student_score add column create_at datetime not null default current_timestamp;
alter table student_score add column update_at datetime not null default current_timestamp on update current_timestamp;
以上两个命令,可以在生成记录或更新记录时,自动生成创建时间和改变更新时间。
3. modify column和change column的区别。
alter table student_score change column score score_num decimal(6,2); alter table student_score modify column score_num decimal(5,2);
网上解释,change可以改变列名称,而modify只是改变列的类型默认值等。总是记不住哪个是可以改变列名臣,再强化一下自己的记忆:
记忆诀窍:change,改变;modify,修改。change的改变比modify程度深,所以change是可以改列名的。
4. 根据某列来判断显示哪些列的数据。
case col_A when val_a then col_B else col_C end as new_col_name case col_A when val_a then col_D else col_E end as new_col_name2
个人工作经历中用到此模式的业务:
O2O:如果商品是系统的,就用系统提供的商品信息;否则就使用商家自己填写的商品信息。
5. 如何避免写给前端的api接口出现null返回值。
select ifnull(col_A, '') as col_A from ... //语句中as也可以省略 select ifnull(col_A, 0) as col_A from ... //语句中as也可以省略
如果col_A列为null,则返回空字符串。
字符型就返回空字符串,数值型就返回0.
alter table student_score add column remarker varchar(30) not null comment '打分人'; insert into student_score(record_id,s_id,subject_id,score,remarker) values('zhai14','1000004',1,77, ''); 6.表的命名设计
此项为本人在工作中总结的经验,如有不妥之处,还请多多指教。
第一点:
表列的名称,如果涵盖多种不同属性的值时,尽量用模糊定义,避免具体名称容易造成开发者及后续新接触的开发人员的误解。
例如某列,即可以存储订单ID,又可以存储用户ID,那么就不要命名成user_id或order_id,命名成subject_id或其他不具体的名称更